DeepSeek переопределяет границы включения больших моделей. 26 апреля DeepSeek официально опубликовал объявление о корректировке цен на API. Цена всех обращений к входному кешу API была снижена до одной десятой от первоначальной цены. На обновление V4‑Pro действует скидка 25 % в течение ограниченного времени, а входной кэш одного миллиона токенов составляет всего 0,025 юаня, что устанавливает новый минимум цен на большие модели в мире.

Согласно объявлению на официальной странице цен на API DeepSeek, это снижение цен распространяется на все модели серии V4, а основные изменения сосредоточены на сценариях попадания в кэш ввода. Среди них цена входного кэша DeepSeek-V4-Flash упала с 0,2 юаня/миллион токенов до 0,02 юаня/миллион токенов.
DeepSeek-V4-Pro для пользователей корпоративного уровня имеет еще большие скидки. Первоначальная цена 1 юань/миллион токенов снижена до 0,1 юаня за ввод в кэш. До 5 мая 2026 года будет добавлено специальное предложение со скидкой 25%, действие которого ограничено по времени, что на самом деле составляет всего 0,025 юаня/миллион токенов. Входная плата за промах в кэше уменьшена с 12 юаней до 3 юаней, а выходная — с 24 юаней до 6 юаней.
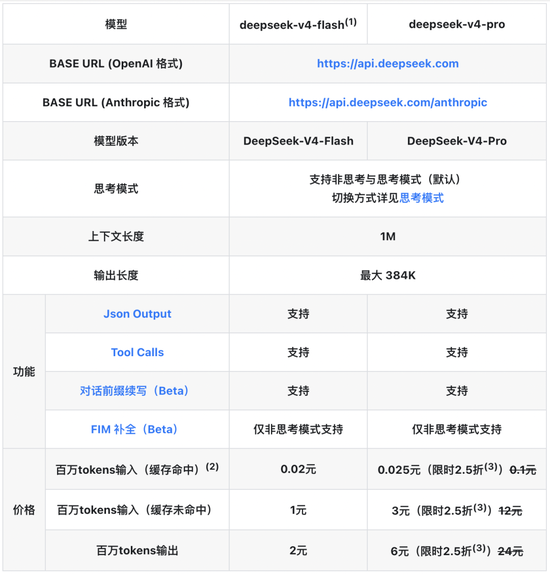
Источник изображения: официальный сайт DeepSeek.
DeepSeek упомянул, что два названия моделей DeepSeek-Chat и DeepSeek-Reasoner в будущем будут устаревшими. По соображениям совместимости эти два режима соответствуют режимам без мышления и мышления DeepSeek-V4-Flash соответственно.
Сравнивая цены до и после корректировки цен, легко обнаружить, что стоимость высокочастотных звонков и сценариев обработки длинных текстов снизилась более чем на 90%. Приложения с высокой частотой обращений к кэшу, такие как базы знаний RAG, интеллектуальная служба поддержки клиентов и анализ документов, могут напрямую обеспечить резкое падение коммерческих затрат, помогая разорвать оковы затрат, связанные с крупномасштабным внедрением ИИ.
Значительное снижение цен на DeepSeek связано с технологическим обновлением DeepSeek‑V4 и углубленным сотрудничеством с экосистемой Shengteng.
24 апреля была официально выпущена предварительная версия DeepSeek‑V4. Модели Pro и Flash с открытым исходным кодом поддерживают сверхдлинные контексты на 1 миллион токенов. Саморазвитая архитектура разреженного внимания значительно снижает потребление вычислительной мощности вывода. Вычислительная мощность версии Pro с одним токеном составляет всего 27% от V3.2, а кэш KV уменьшен до 10%, что обеспечивает оптимизацию затрат снизу вверх.
Параметры, объявленные DeepSeek, показывают, что DeepSeek‑V4‑Pro имеет 49B параметров активации и 33T данных предварительного обучения, что позиционирует его как высокопроизводительный флагман; DeepSeek‑V4‑Flash имеет 13B параметров активации и 32T данных предварительного обучения, что обеспечивает высокую скорость и низкую стоимость.
По сравнению с моделью предыдущего поколения возможности агента DeepSeek-V4-Pro значительно расширены. В оценке агентного кодирования V4-Pro достиг лучшего уровня среди текущих моделей с открытым исходным кодом, а также показал хорошие результаты в других оценках, связанных с агентами. Сообщается, что DeepSeek-V4 стала моделью агентного кодирования, используемой внутренними сотрудниками DeepSeek. Согласно отзывам об оценке, опыт использования лучше, чем у Sonnet 4.5, а качество доставки близко к режиму без мышления Клода Опуса 4.6, но все же существует определенный разрыв с режимом мышления Opus 4.6.
В мировой оценке знаний DeepSeek-V4-Pro значительно опережает другие модели с открытым исходным кодом и немного уступает топовой закрытой модели Gemini-Pro-3.1. При оценке математики, STEM и конкурентных кодов DeepSeek-V4-Pro превзошел все публично оцениваемые в настоящее время модели с открытым исходным кодом и был сопоставим с лучшими в мире моделями с закрытым исходным кодом.
По сравнению с DeepSeek-V4-Pro, DeepSeek-V4-Flash немного уступает по мировому запасу знаний, но демонстрирует близкие возможности рассуждения. Поскольку параметры модели и активации меньше, V4-Flash может предоставлять более быстрые и экономичные услуги API.
DeepSeek-V4 также стал пионером в новом механизме внимания, который сжимает размер токена и сочетает его с разреженным вниманием DSA (DeepSeek Sparse Attention) для достижения лучших в мире возможностей длинного контекста и значительного снижения требований к вычислительной и графической памяти по сравнению с традиционными методами.
Что еще более примечательно, так это то, что вся линейка суперузлов Ascend поддерживает модели серии DeepSeek V4. Это также означает, что DeepSeek выпускает больше сигналов локализации.
В техническом отчете DeepSeek-V4 упоминается: «Детальная схема EP (Expert Parallel) была проверена на двух платформах: NVIDIA GPU и Huawei Ascend NPU. По сравнению с мощной несплавленной базовой версией схема достигла ускорения в 1,50–1,73 раза в общих задачах рассуждения; в сценариях, чувствительных к задержке (таких как развертывание обучения с подкреплением (RL) и высокоскоростных агентских служб), она может достигать ускорения до 1,96 раза».
В DeepSeek подчеркнули, что, поскольку полный спектр продуктов суперузлов Ascend будет запущен партиями во второй половине года, ожидается, что цена версии Pro будет значительно снижена.
После выпуска DeepSeek-V4 Goldman Sachs опубликовал аналитический отчет, в котором указывалось, что основное значение DeepSeek V4 заключается в поддержке внедрения более сложных агентских приложений с меньшими затратами, тем самым открывая новое пространство для масштабирования приложений ИИ. Что касается включения суперузлов Ascend, Goldman Sachs полагает, что ценовая конкурентоспособность DeepSeek будет еще больше укрепляться, создавая условия для более широкого спектра приложений. Кроме того, на фоне продолжающегося ужесточения чипов тенденция миграции топовых китайских моделей искусственного интеллекта на отечественные вычислительные мощности получила явное одобрение ведущих игроков.
В отчете Goldman Sachs также упоминаются сообщения о том, что Tencent и Alibaba ведут переговоры об инвестировании в DeepSeek стоимостью более 20 миллиардов долларов США. Последняя рыночная стоимость Zhipu и MiniMax составляет примерно 53 миллиарда долларов США и 31 миллиард долларов США соответственно. Эта потенциальная сделка отражает логику конкуренции гигантов за дефицитные возможности искусственного интеллекта высшего уровня.
Huatai Securities считает, что рынок легко интерпретирует V4 как «снижение затрат и снижение требований к вычислительной мощности и памяти», но более важным незначительным изменением является то, что после снижения стоимости длинного контекста доступность сложных агентов, многодокументного анализа, долгосрочных задач, онлайн-обучения и других сценариев увеличится, а количество вызовов вывода и частота доступа к хранилищу, как ожидается, возрастут.