27 июня DeepSeek опубликовала технический отчет DSpark и кодовую базу DeepSpec. Базовая модель DeepSeek-V4 не изменилась. Новым является модуль спекулятивного декодирования на стороне сервера: DSpark. DeepSeek очень прямо заявляет об этом на странице модели HuggingFace: V4-Pro-DSpark и V4-Flash-DSpark — «не новые модели». Эти две страницы указывают на одну и ту же контрольную точку модели, а также на версию сервиса после размышлений о декодированном модуле.

Это означает, что DSpark не делает модель вдруг умнее. Его цель – как быстрее и дешевле выдавать ответы после того, как модель появится в сети.
В техническом отчете говорится, что DSpark был развернут в системе онлайн-сервисов DeepSeek-V4. При реальном пользовательском трафике по сравнению с предыдущим производственным базовым уровнем MTP-1, который представляет собой решение DeepSeek для генерации онлайн-спекуляций предыдущего поколения, скорость генерации на одного пользователя V4-Flash увеличивается на 60–85%, а V4-Pro увеличивается на 57–78% при условии, что условия пропускной способности совпадают.
«Быстрое» здесь тоже нужно умерить.В основном это относится к этапу генерации, то есть к скорости, с которой модель продолжает выводить токены. Это не означает, что время сквозного ответа на все запросы пользователей на 85 % быстрее.Предварительное заполнение длинных слов подсказки, извлечение, вызов инструментов, организация очередей и сетевые задержки по-прежнему будут влиять на продолжительность фактического ожидания пользователей.
После того, как модель находится в сети, все еще существует учетная запись вывода.
Эта штука не такая живая, как выпуск новой модели, но она ближе к реальности, с которой ИИ-компании сталкиваются каждый день:Стоимость не заканчивается после обучения модели.
Чат-боты, помощники по написанию кода, агенты и продукты на основе поиска продолжают потреблять время графического процессора при каждом вызове. Если модель медленнее, пользователям придется ждать дольше; если логический вывод будет дороже, производителям будет сложнее открыть высококачественные модели для большего количества сценариев.
За последние два года индустрия искусственного интеллекта все больше привыкла обсуждать затраты на обучение: сколько графических процессоров нужно купить компании, какого размера кластер ей следует построить и сколько будет стоить обучение модели следующего поколения. Но после того, как модель фактически станет продуктом, будет продолжать появляться другой тип затрат: логический вывод.
Обучение похоже на большой проект, а рассуждения — на счет за коммунальные услуги.Пока пользователи задают вопросы, агенты выполняют задачи, а помощники по коду создают исправления, модель будет продолжать потреблять вычислительную мощность.
Крупные модельные сервисы в конечном итоге вернутся к двум показателям: скорости и стоимости единицы токена. Страницы с ценами на API обычно взимают плату на основе входных и выходных токенов, а компании также разделяют различные модели, кэши, маршруты и длину контекста на статьи затрат внутри компании.
DSpark нельзя напрямую приравнивать к снижению цены, но если один и тот же кластер графических процессоров позволяет пользователям быстрее получать ответы при одинаковой пропускной способности, это означает, что одно и то же оборудование может обслуживать больше пользователей или тот же пользовательский опыт может быть обеспечен с меньшим количеством карт.
«Сначала угадай, потом проверь»
Идею спекулятивного декодирования можно примерно понять как «сначала угадай, потом проверь».
Когда большая модель генерирует текст, она обычно выдает токен за токеном. После того, как предыдущий жетон выйдет, следующий жетон будет знать, что взять. Этот метод стабилен, но медленный. Спекулятивное декодирование позволит более легкому проектному модулю заранее угадать токен-кандидат, а целевая большая модель будет проверяться пакетно. Правильная догадка принимается напрямую, а неверная корректируется.
Маленькие модели не могут принимать решения за большие модели. То, какие токены в конечном итоге будут приняты, по-прежнему проверяется целевой моделью; при правильной реализации он меняет метод генерации и не меняет выходное распределение целевой модели.Ускорение достигается за счет того, что крупные модели проверяют кандидатов пакетно, а не постепенно.
Что изменилось в DSpark, так это способ создания черновика.
Статья не останавливается на объяснении «сначала угадай, потом проверь». Основное внимание уделяется тому, как создавать черновики.

Существующие проекты стратегий в целом делятся на две категории. Авторегрессионный составитель более стабилен, поскольку более поздний токен увидит предыдущий токен, но по мере того, как черновик становится длиннее, задержка также увеличивается. Параллельный редактор работает быстрее и может угадать весь абзац сразу, но каждая позиция угадывается отдельно. Более поздние токены легко отсоединяются от предыдущих, и скорость принятия, скорее всего, снизится с течением времени.
DSpark выбирает компромисс.Ключевое слово в названии статьи — «Полуавторегрессивная генерация». Сначала он использует параллельный метод для предложения кандидата, а затем использует упрощенный последовательный уровень для изменения условных отношений последующих токенов. Это не только сохраняет скорость параллельной генерации, но и позволяет последующим кандидатам увидеть то, что было угадано ранее.

Еще одним ключевым моментом является длительность проверки.
Чем больше жетонов-кандидатов вы угадаете, тем меньше вы сэкономите. Если вы знаете, что вторая половина, скорее всего, будет отклонена и все равно передаст ее на проверку крупной модели, вы тратите время GPU на позицию с низкой стоимостью.DSpark будет учитывать уверенность кандидата и текущую загрузку системы, чтобы динамически определять длину проверки.Если графический процессор пуст, вы можете выполнить несколько тестов; когда нагрузка высока, вычислительная мощность резервируется для частей, которые с большей вероятностью будут приняты.
Именно об этом говорит слово «Доверительный план» в названии статьи.

DSpark стоит на существующих технических маршрутах
DSpark придерживается предположения о существующем маршруте декодирования и больше похож на публичный справочник после того, как DeepSeek продвигает этот технический путь в онлайн-сервисы.
SpecInfer внедрил прогнозирование малых моделей, дерево токенов и параллельную проверку в систему обслуживания больших моделей еще в 2023 году; Медуза предложила добавить в модель несколько декодирующих головок в 2024 году, чтобы предсказывать сразу несколько последующих токенов; Серия EAGLE продолжает улучшать уровень принятия черновых моделей и динамических деревьев чертежей. Среды вывода, такие как vLLM, SGLang и TensorRT-LLM, уже давно рассматривают спекулятивное декодирование как важный инструмент для уменьшения задержки.
Преимущество DSpark заключается в том, что он решает несколько производственных задач одновременно: как генерировать черновики, как поддерживать согласованность кандидатов, как длина проверки меняется с нагрузкой и насколько скорость может быть улучшена при реальном онлайн-трафике.
Ключевые слова, которые неоднократно появляются в статье, также перешли от «улучшения возможностей модели» к терминам на стороне обслуживания, таким как скорость генерации для каждого пользователя, согласованная пропускная способность и соглашение об уровне обслуживания (SLA).
Это также объясняет, почему вы не можете просто выбрать наибольшее число для просмотра. В документе действительно есть данные о высокой пропускной способности, такие как 661% и 406%, но они основаны на более строгих целевых показателях скорости для каждого пользователя: при таких настройках старый базовый уровень сам по себе уже близок к границе возможностей сервиса, и относительное преимущество DSpark будет усилено.
Что действительно может проиллюстрировать обычные преимущества, так это предыдущий набор цифр: соответствующая пропускная способность, реальное распределение трафика и объект сравнения — MTP-1.
Что может воспроизвести DeepSpec?
DeepSeek также открыл исходный код DeepSpec. Это библиотека кода для обучения и оценки черновых моделей спекулятивного декодирования. Он включает процессы подготовки, обучения и оценки данных, а также выпускает соответствующие контрольные точки для Qwen3, Gemma и других моделей.
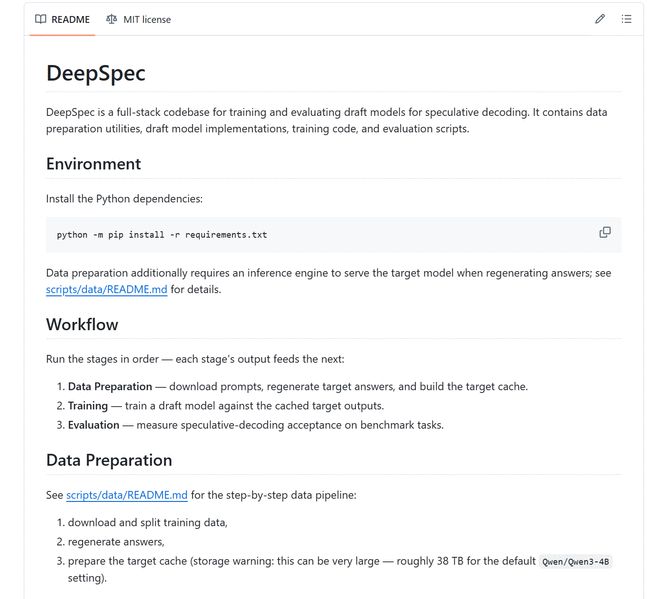
но,Открытый исходный код не означает «скачайте и воспроизведите».В документации проекта указано, что в конфигурации Qwen3-4B по умолчанию кэш целевой модели может составлять около 38 ТБ; сценарий обучения по умолчанию предполагает наличие 8 графических процессоров на одном узле; Если бумажные результаты должны быть согласованы, параметры обучения должны быть строго согласованными, а также потребуется дополнительная тонкая настройка черновой модели в конкретных областях.
Внешний мир может проверить часть метода, а также пересадить DeepSpec на другие модели с открытым исходным кодом, но набор показателей улучшения скорости в онлайн-сервисе DeepSeek-V4 по-прежнему основан на собственном аппаратном масштабе DeepSeek, распределении трафика и планировании производственной системы.
Открытый исходный код — это метод, а не среда.
Сообщество больше всего обеспокоено повторяющимися границами
Обсуждение
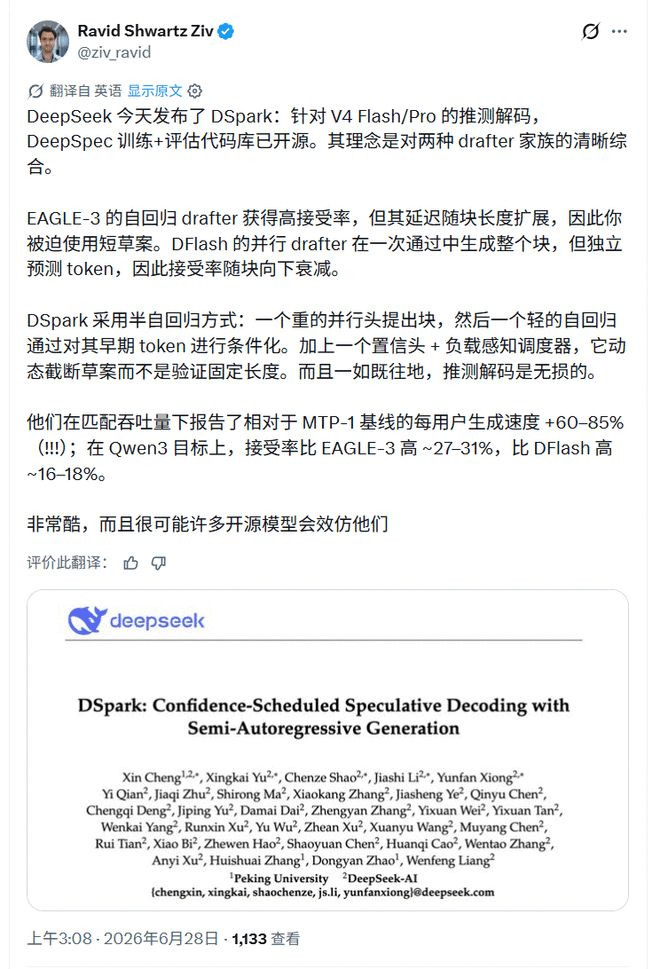
Исследователь искусственного интеллекта Равид ШварцЗив резюмирует DSpark как компромисс между двумя типами составителей: параллельный составитель работает быстро, но скорость принятия падает вдоль блока-кандидата; авторегрессионный драфт стабилен, но задержка увеличивается с увеличением длины драфта. Он особо упомянул два компонента, добавленных в DSpark: блок достоверной оценки и планировщик с учетом нагрузки, а также добавил ключевую границу: «Как и любое спекулятивное декодирование, оно осуществляется без потерь».
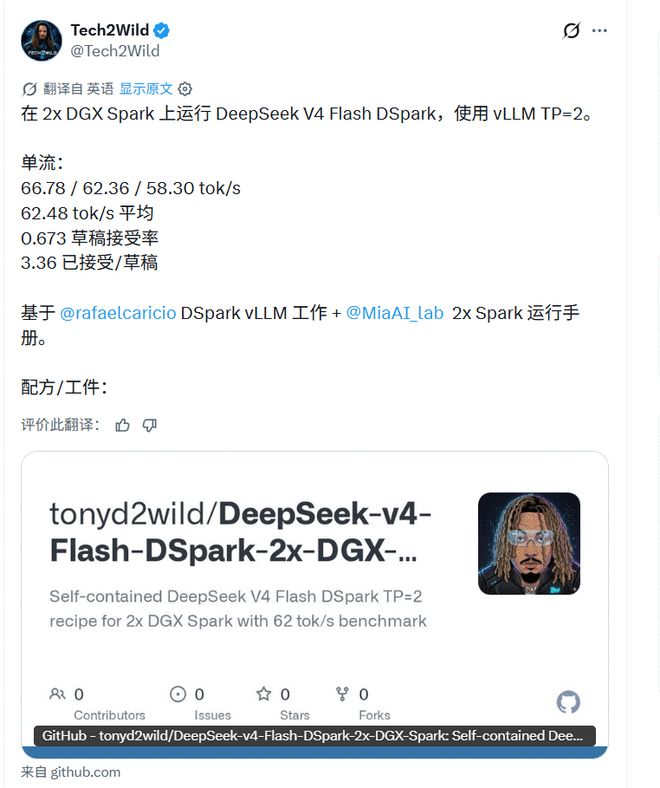
Инженеров больше беспокоит, сможет ли он работать. Участник vLLM Рафаэль Каричио рассказал, что он запускал режим DSpark DeepSeek-V4-Flash на двух DGX Spark GB10, и скорость однопоточного декодирования составила около 60 ток/с, что примерно в 1,5 раза больше, чем у MTP-1.
Он также упомянул, что реальный сеанс кода выявил проблемы, которые не были замечены синтетическими тестами: узким местом является не только скорость вычислительного ядра, но и скорость принятия черновиков значительно снизится в длительном контексте.
Tech2Wild также предоставил данные на месте в аналогичном направлении, показывающие, что V4-Flash-DSpark был протестирован в конкретной среде vLLM. Однако такие результаты сильно зависят от модели оборудования, версии исправления платформы, длины контекста и настроек параллелизма. В другой среде результаты могут быть совершенно другими.
Есть также люди, которые специально напоминают о границах. AcingAI отметила
Это напоминает нам, что отчасти преимущество DSpark связано с планированием с учетом нагрузки, а эффект планирования, естественно, зависит от масштаба трафика и конфигурации оборудования производственной среды.
Та же мощность, меньше вычислительной мощности
В отчете от 28 июня газета South China Morning Post рассмотрела DSpark с точки зрения узких мест, нагрузки на чипы и времени ожидания пользователей. Эта точка зрения ближе к реальности продукта, чем вопрос «Какую модель снова выпустила DeepSeek?»
Компании, занимающиеся искусственным интеллектом, продолжат сравнивать возможности моделей, но когда разрыв в возможностях сократится, участниками конкуренции станут те, кто сможет предоставить те же возможности быстрее и дешевле.
Такие компании, как DeepSeek, особенно должны прояснить это. DeepSeek всегда рассматривал низкую стоимость и высокую эффективность как важную отправную точку для внешнего мира, чтобы понять это. От повествования об обучении модели до цены API, наибольшее внимание привлекает не то, имеет ли он больший масштаб параметров, а то, может ли он сделать те же возможности дешевле.
DSpark продолжает эту линию: он не доказывает, что V4 внезапно стал умнее, он доказывает, что V4 может тратить меньше вычислительной мощности при обслуживании пользователей.
Если мы немного расширим нашу перспективу, оптимизация вывода также повлияет на экологию модели с открытым исходным кодом. Модель с открытым исходным кодом раньше считалась «дешевой», но когда она будет фактически развернута, графическая память, пропускная способность, параллелизм, задержка, а также сложность эксплуатации и обслуживания станут затратами.
Если исходный код модели может быть открытым, это означает лишь то, что каждый может получить ее; сможет ли он дешево обслуживать большое количество пользователей, зависит от того, сможет ли стек вывода справиться с этой задачей.
DeepSpec выпустила Qwen3, Gemma и другие контрольно-пропускные пункты, что указывает на то, что на самом DeepSeek-V4 это дело не ограничивается. Степень миграции зависит от фактического прогресса адаптации сообщества, поддержки платформы и совместимости оборудования; но, судя по текущей публичной информации, DeepSeek исключил этот путь из своей модели.
В этом заключается ценность DSpark.Он добавляет в V4 уровень инструментов службы вывода, который ближе к производственной системе, а не просто новую метку возможностей.
Далее стоит посмотреть не только то, насколько быстро может работать DeepSeek, но и то, сколько людей смогут пройти по этому маршруту. DeepSpec выпустила контрольные точки и процессы обучения, и предполагается, что декодирование превращается из инженерного выбора компании в распространенное средство вывода с открытым исходным кодом для снижения затрат.Это при условии, что другие платформы и оборудование смогут не отставать.