Плохая новость заключается в том, что разрыв между моделями с открытым и закрытым исходным кодом становится все шире и шире. Хорошие новости: DeepSeek снова в деле. 1 декабря DeepSeek выпустила две новые модели — DeepSeek V3.2 и DeepSeek-V3.2-Speciale.
Первый может конкурировать с GPT-5 туда и обратно, а более поздняя высокопроизводительная версия прямо взорвала GPT и начала отставать 50-50 от модели потолочного типа Gemini с закрытым исходным кодом.
Он также выиграл золотые медали в серии соревнований, таких как IMO 2025 (Международная математическая олимпиада) и CMO 2025 (Китайская математическая олимпиада).
Это девятая модель компании в этом году, хотя долгожданного R2 еще нет.
Итак, как же DeepSeek использует меньшие объемы данных и меньшее количество видеокарт для создания модели, способной конкурировать с международными гигантами?
Мы открыли их газету и хотели всем доходчиво объяснить этот вопрос.
Для достижения этой цели DeepSeek реализовал множество новых трюков:
Сначала наш старый друг DSA — Dirty Attention превратился в обычный.
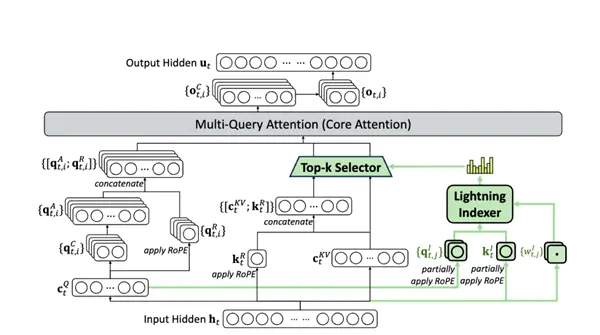
Эта штука появилась в предыдущей версии V3.2-EXP. В то время мы как раз тестировали, повлияет ли DSA на производительность модели. Теперь мы действительно поставили эту штуку на основную модель.

Когда вы обычно общаетесь с крупными моделями, вы обнаружите, что чем больше вы болтаете в диалоговом окне, тем легче модели говорить чепуху.
Даже если они говорят слишком много, они не дадут вам поговорить напрямую.

Эта проблема вызвана встроенным механизмом внимания больших моделей. Под влиянием этой старой логики каждый токен должен рассчитываться вместе с каждым предыдущим токеном.

Это приводит к удвоению предложения, а объем вычислений модели приходится увеличивать в четыре раза. Если длина стороны увеличится втрое, то сумма расчета увеличится в девять раз, что очень хлопотно.
В DeepSeek решили, что это не сработает, поэтому добавили к большой модели фиксированное количество страниц каталогов (редкое внимание), что эквивалентно помощи модели в фокусировке.
После того, как у вас есть оглавление, вам нужно только каждый раз в дальнейшем рассчитывать связь между этим токеном и этими каталогами. Это эквивалентно первому чтению оглавления при чтении книги. Прочитав оглавление, вы сможете определить, какая глава вас интересует, а затем внимательно прочитать содержание этой главы.
Таким образом, способность крупных моделей читать длинные тексты станет сильнее.
Как вы можете видеть на рисунке ниже, по мере того, как предложения становятся все длиннее и длиннее, затраты на рассуждения в традиционной версии V3.1 становятся все выше и выше.
Но при использовании 3.2 с редким вниманием изменений нет...

Я супер-чемпион по экономии денег.
С другой стороны, DeepSeek начал уделять внимание работе с моделями с открытым исходным кодом после обучения.
Процесс от предварительного обучения до оценки результатов тестов для большой модели на самом деле немного похож на процесс, который мы, люди, начинаем с начальной школы и учимся вплоть до вступительных экзаменов в колледж.
Предыдущая масштабная предварительная подготовка эквивалентна изучению всех учебников, тетрадей и сочинений от начальной школы до второго класса средней школы. Этот шаг одинаков для всех. Будь то модель с закрытым исходным кодом или модель с открытым исходным кодом, все они учатся честно.
Но все по-другому, когда дело доходит до спринтерского этапа вступительных экзаменов в колледж. На этапе постобучения модели модели с закрытым исходным кодом обычно нанимают известных учителей, чтобы они освежили вопросы, начали различное обучение с подкреплением и, наконец, позволили модели достичь хороших результатов в тесте.
Однако модели с открытым исходным кодом тратят на это меньше времени. По данным DeepSeek, объем вычислительных инвестиций в предыдущие модели с открытым исходным кодом на этапе после обучения в целом был низким.
Это приводит к тому, что эти модели могут иметь базовые возможности, но в них слишком мало сложных задач, которые нужно решить, что приводит к плохим результатам тестов.
Поэтому компания DeepSeek решила на этот раз пройти курс обучения у известных учителей и разработала новый протокол обучения с подкреплением. После предварительного обучения было потрачено более 10% общей вычислительной мощности обучения на внесение небольших улучшений в модель, чтобы восполнить недостающую часть.
Параллельно была выпущена и специальная версия, которая может долго думать — DeepSeek V3.2 Speciale.
Идея этой вещи заключается в следующем:
Раньше большие модели имели ограничения на длину контекста, поэтому во время обучения им приходилось выполнять некоторую работу по маркировке и штрафам. Если содержание углубленного размышления модели было слишком длинным, баллы вычитались.
Что касается DeepSeek V3.2 Speciale, то DeepSeek просто отменил этот пункт вычета.Вместо этого модели предлагается думать так долго и так, как она хочет.
В конце концов, этот новый DeepSeek V3.2 Speciale несколько дней назад успешно конкурировал с популярным Gemini 3.
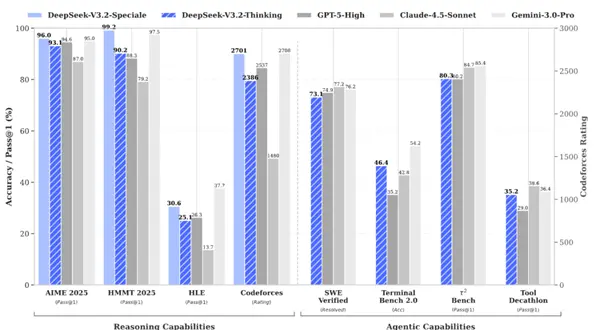
Кроме того, DeepSeek также придает большое значение возможностям модели с точки зрения интеллектуальных агентов.
С одной стороны, чтобы улучшить базовые возможности модели, DeepSeek создала виртуальную среду и синтезировала тысячи фрагментов данных для облегчения обучения.
DeepSeek-V3.2 использует 24667 задач среды реального кода, 50275 задач реального поиска, 4417 сценариев синтетического общего агента и 5908 задач интерпретации реального кода для постобучения.

С другой стороны, DeepSeek также оптимизирует процесс использования различных инструментов для модели.
Типичная проблема предыдущих поколений DeepSeek заключается в том, что они отделяют мышление от использования инструментов.
Как только модель вызывает внешний инструмент, предыдущая часть мышления в основном завершается и работа завершена. Когда инструмент возвращается после проверки результатов, ему часто приходится заново излагать идеи.
Это приводит к очень глупому опыту — даже если вы просто проверите такую простую вещь, как «какая сегодня дата», модель перестроит всю цепочку рассуждений с нуля, а это огромная трата времени…
В V3.2 DeepSeek не выдержал и прямо отменил эту логику и переделал ее.
Теперь правила стали такими:В течение целой серии вызовов инструмента «процесс мышления» модели будет сохраняться. Только когда пользователь отправит новый вопрос, этот раунд рассуждений будет сброшен; а записи и результаты вызовов инструментов останутся в контексте, как записи чата.
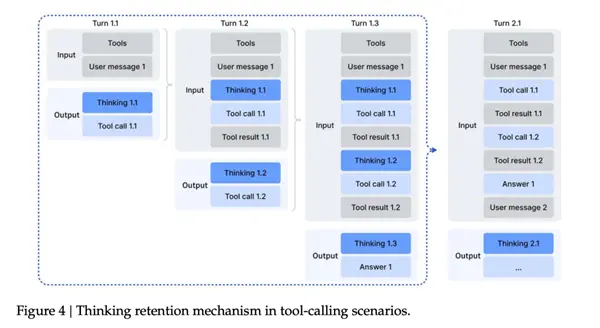
Благодаря этим трем шагам изменения архитектуры модели, уделению внимания постобучению и усилению возможностей агента, DeepSeek наконец-то дала своей новой модели возможность снова конкурировать с ведущими в мире моделями с открытым исходным кодом.
Конечно, даже несмотря на такое количество улучшений, производительность DeepSeek не идеальна.
Но что Тони больше всего нравится в DeepSeek, так это их готовность признать свои недостатки.
И это будет написано прямо в газете.
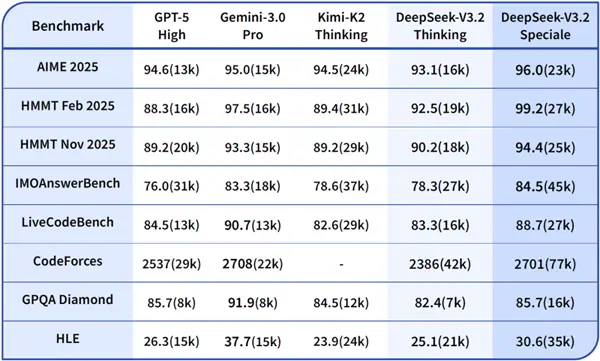
Например, в этой статье упоминается, что на этот раз DeepSeek V3.2 Speciale может конкурировать 50 на 50 с Gemini 3 Pro от Google.

Но чтобы ответить на тот же вопрос, DeepSeek нужно потратить больше токенов.
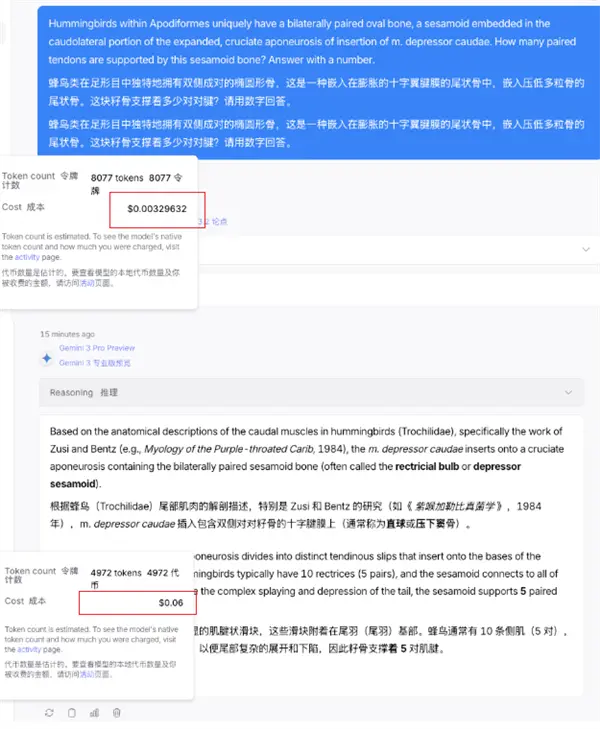
Я также протестировал его сам, случайно выбрал вопрос из банка вопросов «Выпускного экзамена человечества» и одновременно бросил его двум моделям Gemini 3 Pro и DeepSeek V3.2 Speciale.

Тема:
Колибри уникальны среди подоморфов тем, что обладают двусторонне парными овальными костями, хвостовой костью, встроенной в расширенный крестообразный апоневроз, который угнетает многозернистые кости. Сколько пар сухожилий поддерживает эта сесамовидная кость? Пожалуйста, ответьте цифрами.
Оказывается, Близнецам нужно всего 4972 жетона, чтобы ответить на вопрос.

Что касается DeepSeek, то для решения проблемы потребовалось 8077 токенов.

Если посмотреть на использование, потребление токенов DeepSeek почти на 60% выше, что действительно является большим разрывом.
Но опять же.
Хотя DeepSeek потребляет много токенов, его цена невысока...
Все еще задавая тот же вопрос, я внимательно посмотрел на счет.
DeepSeek 8000+ токенов обошлись мне в 0,0032 доллара.
Но со стороны Google это стоило мне менее 5000 токенов, а мне это стоило 0,06 доллара? Это в 20 раз выше, чем у DeepSeek.
С этой точки зрения я считаю, что DeepSeek лучше...
Наконец, вернемся к началу статьи.
Как заявили в DeepSeek, разрыв между моделями с открытым исходным кодом и моделями с закрытым исходным кодом за последние шесть месяцев увеличился.

Но они по-прежнему используют свой собственный способ наверстать упущенное.
Различные операции DeepSeek по энергосбережению и сохранению данных напомнили мне интервью с Ильей Суцкевером в прошлом месяце.

Бывшая душа OpenAI считает, что будущего нет, если просто слепо добавлять параметры в модель.
AlexNet использует только два графических процессора. Когда Transformer только появился, масштаб экспериментов в основном находился в диапазоне от 8 до 64 графических процессоров. По сегодняшним меркам это даже эквивалентно размеру нескольких графических процессоров, то же самое касается ResNet.Ни одна статья не может быть завершена без огромного кластера.
По сравнению с накоплением вычислительной мощности исследование алгоритмов не менее важно.
Именно этим и занимается DeepSeek.
От MoE V2 до многоголового скрытого внимания (MLA) V3 и современного механизма самопроверки DeepSeek Math V2 и разреженного внимания (DSA) V3.2.
DeepSeek показывает нам прогресс, который никогда не бывает единичным и основан на улучшениях, вызванных масштабированием параметров стека.
Вместо этого мы думаем о том, как использовать ограниченные данные для накопления большего количества информации.
Умная женщина выставляет себя дурой
Итак, когда выйдет R2?