18 июня исследователь мультимодальных систем DeepSeek Чэнь Сяокан сообщил, что режим распознавания изображений DeepSeek официально запущен в Интернете и в приложении. Запрос показал, что режим распознавания изображений на стороне приложения DeepSeek по-прежнему выдает сообщение «Функция распознавания изображений находится на внутреннем тестировании», но на веб-странице такого запроса нет.
Однако медиа-тесты показали, что DeepSeek менее точен в идентификации людей. Например, он не мог узнать своего босса Лян Вэньфэна. В один момент он узнал в нем Ван Сина, а в другой момент узнал в нем кого-то другого.


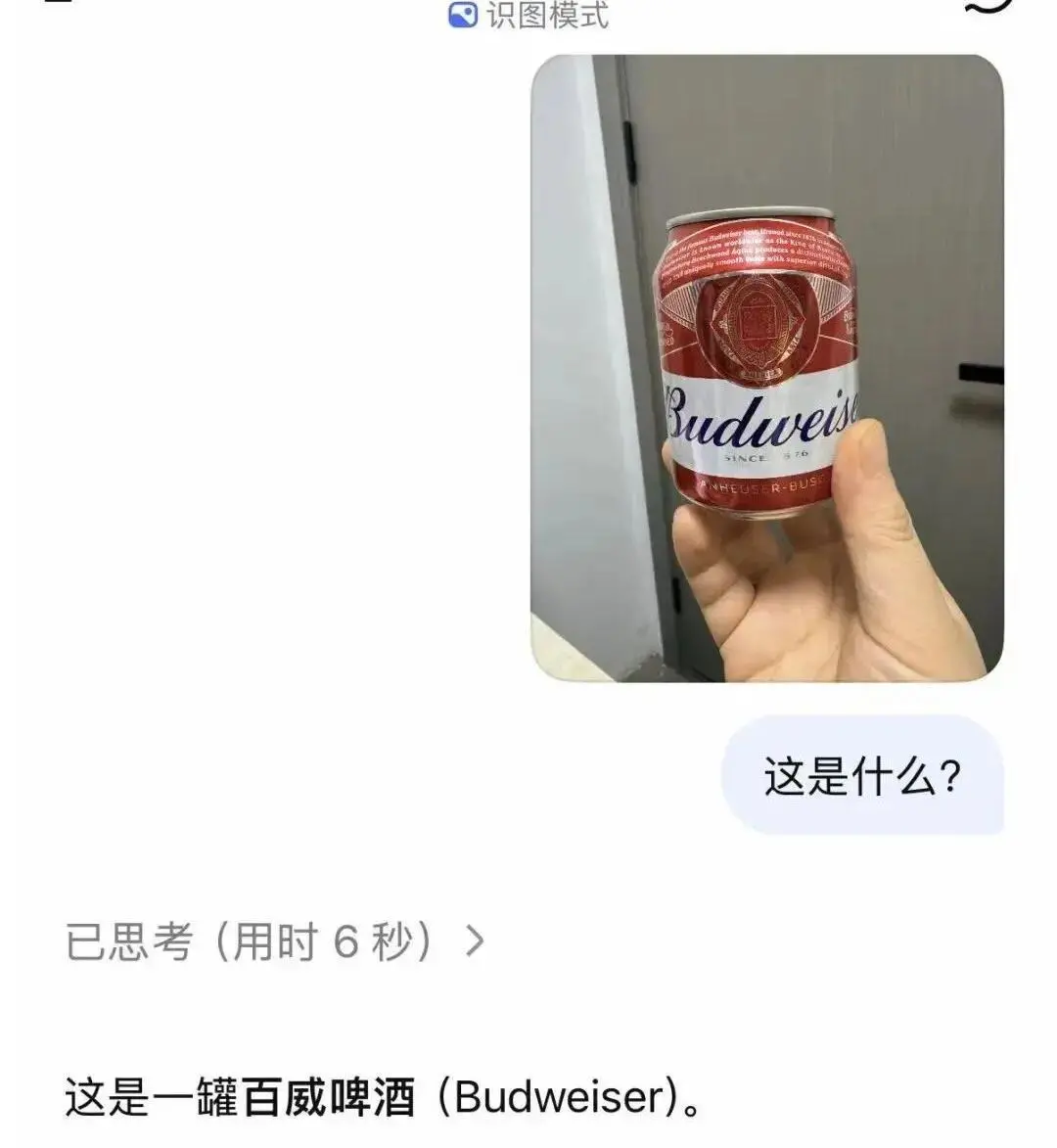
Однако идентификация обычных объектов и известных зданий оказалась относительно точной.
По имеющимся данным, два месяца назад режим распознавания изображений DeepSeek был официально запущен в оттенках серого. Режим распознавания изображений DeepSeek, являющийся собственным порталом визуального взаимодействия, представляет собой независимую функцию первого уровня наряду с быстрым режимом и экспертным режимом. Он полностью избавляется от ограничений возможностей ранних моделей чистого текста и обеспечивает интегрированный диалог с изображениями и текстом.
Следует напомнить, что режим распознавания изображений DeepSeek — это не простой инструмент извлечения текста изображения или простой инструмент оптического распознавания символов, а основан на самостоятельно разработанном механизме визуального причинно-следственного потока DeepSeek-OCR2 для создания замкнутого цикла полного визуального понимания. Пользователям нужно только напрямую загружать изображения с текстовыми вопросами, и система может одновременно выполнять распознавание объектов, анализ сцены, разборку диаграммы, точное извлечение текста и подробный анализ.
Сообщается, что DeepSeek недавно завершила финансирование серии А с суммой финансирования около 51 миллиарда юаней и постинвестиционной оценкой компании примерно в 400 миллиардов юаней.