Предварительная версия DeepSeek-V4 наконец-то выпущена. Сегодня компания DeepSeek официально объявила о выпуске и открытом исходном коде двух моделей, deepseek-v4-pro и deepseek-v4-flash, со сверхдлинным контекстом в миллион слов. С этого момента вы можете войти на официальный сайт или в официальное приложение, чтобы поговорить с новейшей версией DeepSeek-V4 и изучить новые возможности сверхдлинной контекстной памяти объемом 1 миллион (миллионов). Служба API была обновлена одновременно.

Текст | Колонка «ОШИБКА» Чжоу Вэньмэн

Согласно официальной сравнительной оценке, производительность DeepSeek V4 сопоставима с лучшими международными моделями с закрытым исходным кодом с точки зрения длины контекста, знаний, рассуждений и возможностей агента и достигла первоклассного уровня международных моделей с открытым исходным кодом. Сравнение в столбце «Ошибка» показало, что с точки зрения цен на вызовы API версия DeepSeek V4, которая в прошлом году единолично привела к снижению цен в отечественной индустрии крупных моделей, снова установила «самую низкую цену» в отрасли.
«Хотя цена вызова за миллион токенов отечественных моделей не сильно снизилась, большая длина контекста и хорошая производительность дают ему очень конкурентное преимущество!» Некоторые люди в отрасли сетовали, общаясь с колонкой «Ошибка»: «Этот мясник с большими ценами на модели вернулся!»
Производительность сравнима с лучшими моделями с закрытым исходным кодом, а знания и способности рассуждения являются ведущими.
Согласно официальному представлению DeepSeek, серия V4 включает две версии модели: DeepSeek-V4-Pro с общими параметрами 1,6T, параметрами активации 49B и данными предварительного обучения 33T; DeepSeek-V4-Flash с общим количеством параметров 284B, параметрами активации 13B и данными предварительного обучения 32T; оба изначально поддерживают 1 миллион контекстов токенов.
Согласно данным эталонных тестов, раскрытым DeepSeek, в тестах на знание и рассуждение DeepSeek-V4-Pro-Max показал наилучшие результаты в тестах Apex Shortlist и Codeforces, превзойдя такие международные модели, как Claude-Opus-4.6-Max, GPT-5.4-xHigh, Gemin-3.1-Pro-Hight и т. д., продемонстрировав сильные логические и алгоритмические возможности; в SimpleQA. В проверенном тесте он немного отстает от Gemini-3.1-Pro-High, но опережает Claude и GPT.
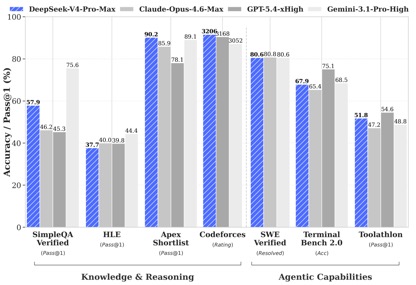
В оценке агентных возможностей три модели V4, Opus-4.6 и Gemin-3.1-pro были привязаны к задаче SWE Verified, а DeepSeek достиг второго уровня после GPT-5.4-xHigh в задаче Toolathlon и достиг уровня выше, чем Opus-4.6 в Terminal Bench 2.0, что отражает ее преимущества в сложных сценариях выполнения команд и вызовов инструментов.
В настоящее время DeepSeek-V4 стала моделью агентного кодирования, используемой внутренними сотрудниками компании. Согласно отзывам об оценке, опыт использования лучше, чем у Sonnet 4.5, а качество доставки близко к режиму без мышления Opus 4.6.
При оценке математики, STEM и конкурентных кодов DeepSeek-V4-Pro превзошел большинство моделей с открытым исходным кодом, прошедших публичную оценку, и достиг результатов, сопоставимых с лучшими в мире моделями с закрытым исходным кодом.
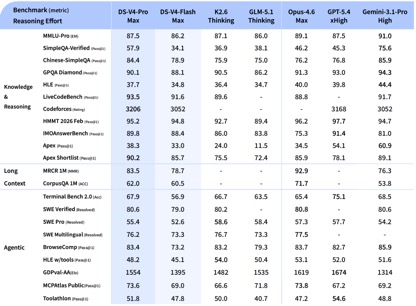
В совокупности с точки зрения возможностей обработки знаний и рассуждений DeepSeek-v4 достиг абсолютного превосходства над отечественными моделями с открытым исходным кодом и сопоставим с международными возможностями оценки. Однако с точки зрения агентных возможностей, хотя последняя версия DeepSeek-v4 добилась хороших улучшений, разрыв между внутренними и международными возможностями первого уровня не увеличился, и каждый из них находится впереди.
"Стандартная конфигурация: 1 миллион контекстов,Прайс-мясник «возвращается»
По сравнению с преимуществами производительности, отраженными в различных тестах производительности, самой большой особенностью этой версии V4 является прорыв в возможностях длинного текста и дальнейшее снижение стоимости вызовов API.
Благодаря новому механизму внимания, впервые реализованному в DeepSeek-V4, V4 обеспечивает лучшие в мире возможности длинного контекста за счет сжатия размера токена и объединения его с разреженным вниманием DSA (DeepSeek Sparse Attention), а также значительно снижает требования к вычислительной и графической памяти по сравнению с традиционными методами, делая 1M (один миллион) контекста стандартом для всех официальных сервисов DeepSeek.
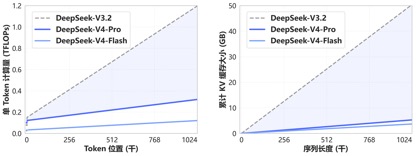
Год назад 1 миллион контекстов был эксклюзивным козырем Gemini. Даже в большинстве недавно выпущенных отечественных моделей с открытым исходным кодом длина контекста модели в основном находилась в диапазоне 128–200 тыс. Однако DeepSeek напрямую преобразовал миллион контекстов из «высококлассной функции с закрытым исходным кодом» в стандарт с открытым исходным кодом.
Что касается ценовых вызовов API, по сравнению с текущей ценой входной единицы GLM-5.1, составляющей 1,3-2 юаня/миллион токенов (попадание в кэш) и Kimi-K2.6 1,1 юань/миллион токенов (попадание в кэш), цены входной единицы для DeepSeek-v4-pro и флэш-версий составляют 1 юань/миллион токенов и 0,2 юаня/миллион токенов соответственно. Падение цены хоть и небольшое, но минимальное, а длина контекста увеличена в несколько раз.
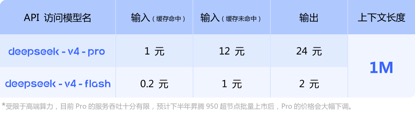
(Цена вызова API для модели серии DeepSeek-v4)
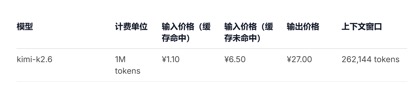
(Цена вызова API модели Kimi-k2.6)
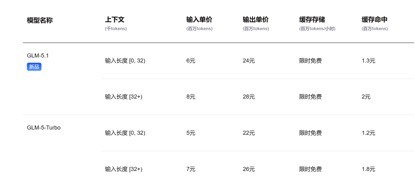
(Цена вызова API модели GLM-5.1)
«Прорыв в производительности, достигнутый выпуском DeepSeek-v4, менее впечатляющий, чем выпуск DeepSeek-R1. Производительность все еще находится в первом эшелоне, но лидерство еще не расширено полностью». По мнению инсайдеров отрасли, «выпуск модели V4 больше связан с улучшением возможностей работы с длинным текстом и дальнейшим снижением цены».
Этот человек посетовал: «После выпуска моделей DeepSeek-V3 и R1 преимущества в производительности, обеспечиваемые базовыми технологическими инновациями, напрямую способствовали коллективному снижению цен во всей отечественной индустрии крупных моделей. Хотя цена вызова за миллион токенов версии V4 не сильно упала по сравнению с отечественными аналогами, она по-прежнему конкурентоспособна. Мясник цен на большие модели вернулся!»
«Вычислительные мощности Huawei будут добавляться партиями во второй половине года, а цена Pro будет значительно снижена».
Стоит отметить, что в нижней части информации о ценах на API, опубликованной DeepSeek-v4, в официальном уведомлении говорится: «Пропускная способность сервиса Pro, ограниченная высокопроизводительной вычислительной мощностью, в настоящее время очень ограничена. Ожидается, что цена Pro будет значительно снижена после запуска суперузла Ascend 950 партиями во второй половине года».

Это означает, что выпущенные на этот раз модели серии v4 были адаптированы к суперузлу Huawei Ascend 950. Пока Ascend 950 будет выпущен, пользователи смогут использовать DeepSeek-v4 на базе отечественной вычислительной мощности, сравнимой с лучшими международными моделями с закрытым исходным кодом.
В официальной технической документации с открытым исходным кодом компания DeepSeek также упомянула об этом, заявив, что версия 4 проверила детальное решение EP (Expert Parallelism) на платформах NVIDIA GPU и HUAWEI Ascend NPU. По сравнению с мощной базовой версией без слияния, он может достигать ускорения в 1,50–1,73 раза при выполнении общих задач рассуждения и может достигать ускорения в 1,96 раза в сценариях, чувствительных к задержкам (таких как вывод RL и высокоскоростные прокси-сервисы).

После выпуска V4 компания Huawei Ascend также объявила, что «весь ассортимент продуктов суперузла поддерживает модели серии DeepSeek V4». Сообщается, что Ascend 950 снижает накладные расходы на вычисление внимания и доступ к памяти за счет интеграции ядра и технологии многопоточного параллельного анализа, значительного повышения производительности вывода и объединения нескольких алгоритмов квантования для достижения высокой пропускной способности и низкой задержки развертывания вывода модели DeepSeek V4.
Ранее в этом месяце основатель Nvidia Хуан Дженсюнь заявил в эксклюзивном интервью Дваркешу Пателю: «Если DeepSeek сначала будет выпущен на платформе Huawei, это будет катастрофой для нашей страны (Соединенных Штатов)». По мнению Хуанга, хотя DeepSeek является моделью с открытым исходным кодом и может также использоваться в продуктах Nvidia, если DeepSeek специально оптимизирован для вычислительной мощности Huawei, Nvidia окажется в невыгодном положении из-за таких ограничений, как ограничения на покупку высокопроизводительных вычислительных мощностей.
Теперь кажется, что, хотя DeepSeek также проверил решение EP для вычислительной мощности Nvidia, то, о чем беспокоился Хуан Ренсюнь, все же произошло. По мнению инсайдеров отрасли, «V4 — это продукт, вызванный игрой в вычислительную мощность. В следующем году отечественные большие модели, работающие на отечественных картах, постепенно станут зрелыми».
Мультимодальные возможности еще не появились
К сожалению, несмотря на выпуск DeepSeek V4, эта версия по-прежнему представляет собой чисто текстовую модель без многих мультимодальных возможностей, таких как изображения Винсента и видео Винсента. Это также позволяет обычным пользователям быстро опробовать и оценить модель, что значительно усложняет работу.

В конце концов, поскольку возможности больших языковых моделей продолжают улучшаться, а уровень галлюцинаций постепенно снижается, традиционным и единым вопросам и ответам на знания становится трудно объективно отражать всеобъемлющие возможности модели. Большинству пользователей, если они хотят интуитивно ощутить возможности модели V4, им приходится скачать ее и какое-то время использовать лично.
Одновременно с выпуском моделей серии V4 компания DeepSeek недавно сообщила, что планирует привлечь 50 миллиардов юаней. Люди, близкие к DeepSeek, сообщили, что предварительная оценка DeepSeek составляет 300 миллиардов юаней, примерно 44 миллиарда долларов США. В настоящее время Tencent Holdings и Alibaba Group ведут переговоры об инвестировании в DeepSeek. Однако DeepSeek не ответила напрямую на запросы СМИ по вопросам финансирования.
Возможно, для основателя DeepSeek Лян Вэньфэна также является мудрым шагом использовать выпуск V4 для привлечения своевременного финансирования для укрепления своей силы, когда рост «интеллекта» глобальных больших моделей замедляется, конкуренция за отраслевые таланты усиливается, а мультимодальные и агентские тенденции в отрасли все более выявляются.